Steam Data Exploration in Python
In the previous posts in this series we successfully downloaded and cleaned a whole dataset from Steam and Steamspy. Today we're going to be diving into that dataset, getting to grips with it, and trying to get a sense of the gaming industry as a whole. We'll try to focus on questions like 'What makes a game great?' and 'What do the most popular games look like?'. Our answers will relate specifically to the Steam environment, but hopefully we'll be able to uncover some interesting insights that we can relate to the wider video game industry.
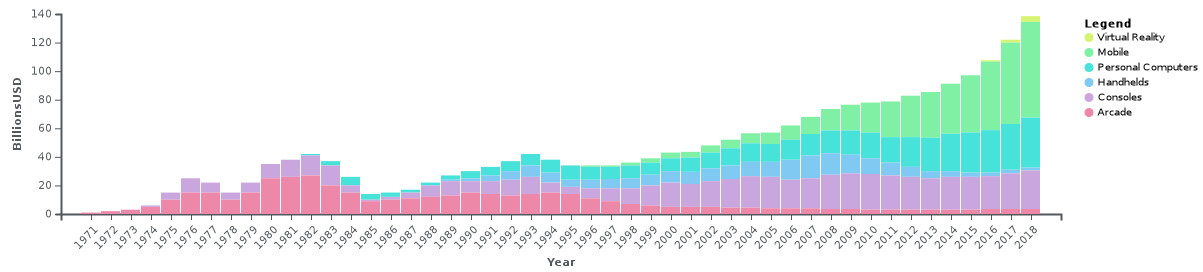 Global revenues of the video game industry from 1971 to 2018, not adjusted for inflation. Source: Wikipedia
Global revenues of the video game industry from 1971 to 2018, not adjusted for inflation. Source: Wikipedia
Comparable in size to the film and music industry in the UK, and generating more than double the revenue of the film industry internationally, the video game industry is huge. Knowing how to navigate this landscape would be invaluable, so let's begin that process. In this post we'll be exploring the data, trying to make sense of it through visualisations in a process commonly referred to as Exploratory Data Analysis (EDA).